

Founders Story
When Discord Chats Spark Billion-Dollar Ideas


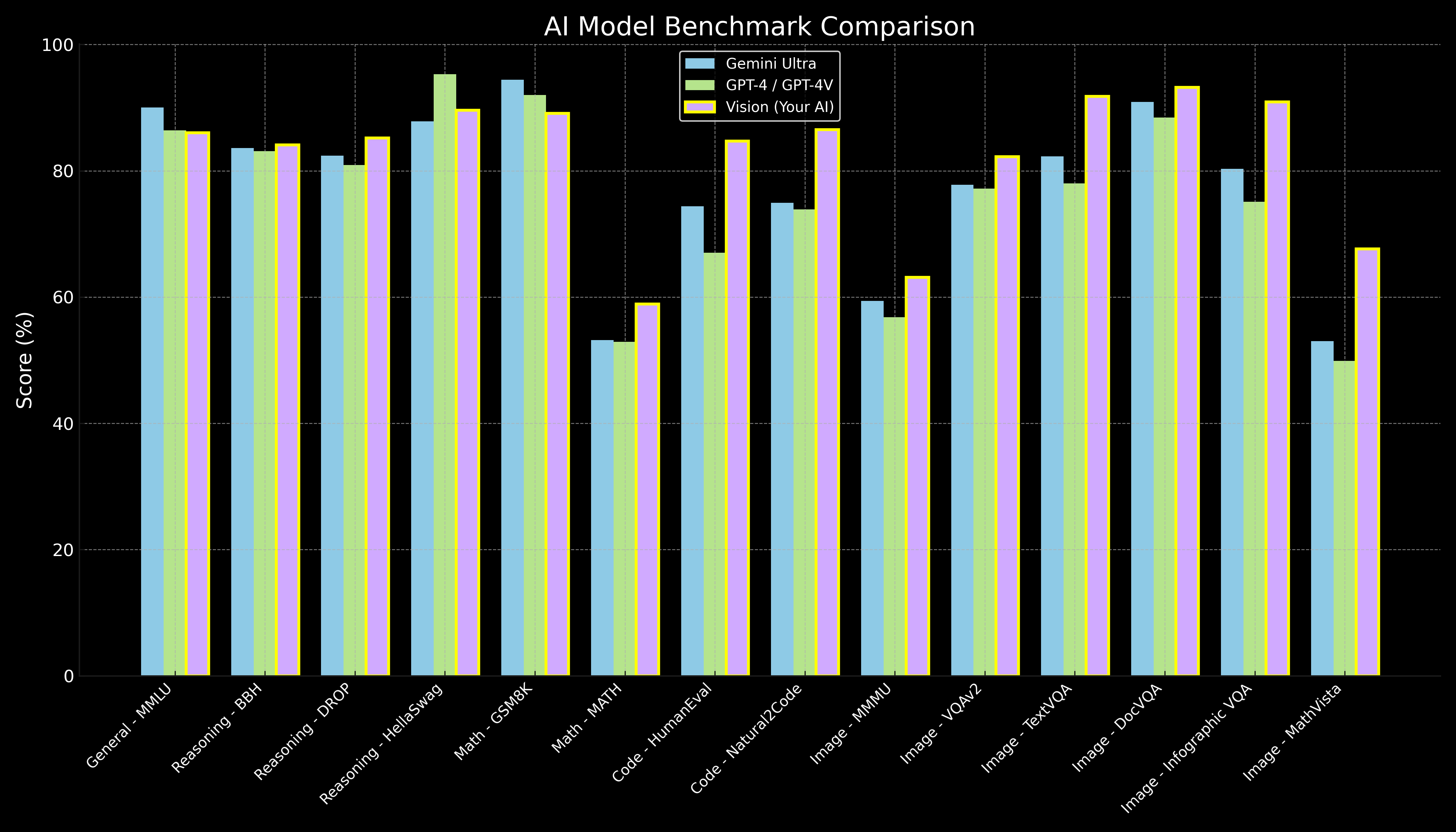
| Category | Benchmark | Gemini Ultra | GPT-4 / GPT-4V | Vision (Rose) |
|---|---|---|---|---|
| General | MMLU | 90.0% | 86.4% | 86.0% |
| Reasoning | Big-Bench Hard | 83.6% | 83.1% | 84.1% |
| DROP | 82.4 | 80.9% | 85.2% | |
| HellaSwag | 87.8% | 95.3% | 89.6% | |
| Math | GSM8K | 94.4% | 92.0% | 89.1% |
| MATH | 53.2% | 52.9% | 58.9% | |
| Code | HumanEval | 74.4% | 67.0% | 84.7% |
| Natural2Code | 74.9% | 73.9% | 86.5% | |
| Image (Multimodal) | MMMU | 59.4% | 56.8% | 63.1% |
| VQAv2 | 77.8% | 77.2% | 82.2% | |
| TextVQA | 82.3% | 78.0% | 91.8% | |
| DocVQA | 90.9% | 88.4% | 93.2% | |
| Infographic VQA | 80.3% | 75.1% | 90.9% | |
| MathVista | 53.0% | 49.9% | 67.6% |
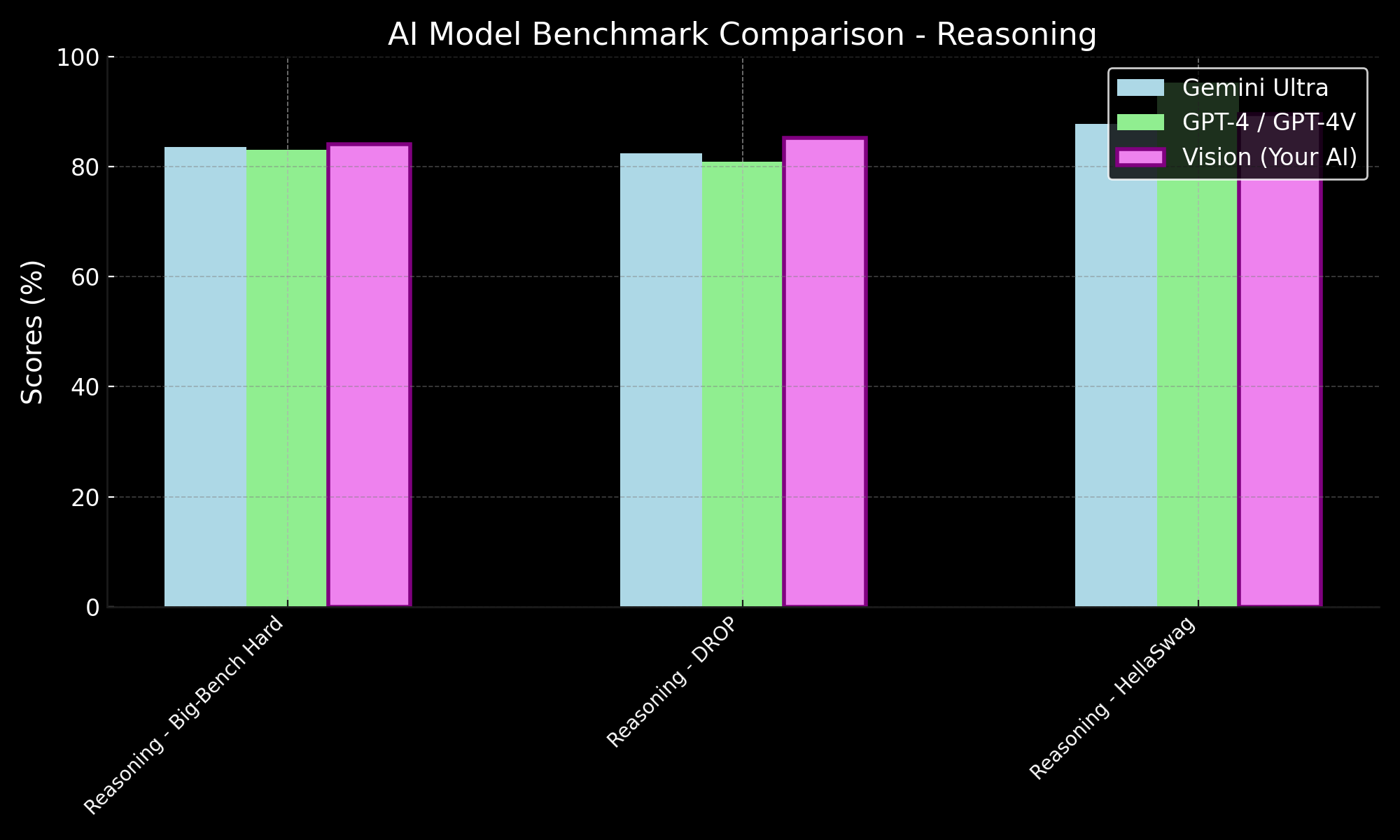
ROSE's reasoning advantage comes from its multimodal foundation:
Contextual Understanding: Processes not just words, but meaning, intent, and emotional context.
Persistent Memory: Maintains reasoning threads across long conversations
Cultural Intelligence: Reasons about cultural nuances and appropriate responses
Real-time Inference: Applies complex logical reasoning while generating speech

““we are outpacing OpenAI, Google, and Meta with a better model, built on far less compute and at a fraction of the cost.””
ROSE represents the first speech-to-speech model backed by foundational reasoning intelligence. By inheriting Vision AI's proven reasoning capabilities, outperforming both GPT-4 and Gemini across multiple cognitive benchmarks, ROSE doesn't just sound human, it thinks and reasons like one. This foundation enables conversations that are not only natural but genuinely intelligent.
"We're not just building voice AI, we're creating the third dimension of human-machine conversation. While others focus on words, we capture the soul of speech: the tonality, the pauses, the emotional nuances that make us human.
Our AI doesn't just respond; it learns, gains experience, and grows wiser with every conversation, just like we do. We're not making machines sound human, we're making them understand what it means to be human."
— Tanusri & Vansh, Co-founders of AIVoco





