







Aivoco's Story
August 15, 2025
Story Behind India's First Speech to Speech Model


Forget School Projects — The Spark That Started It All
Forget school projects, the true fire for Vansh ignited in 2019 when he was just 12 years old. Picture this: all his friends were chatting it up on WhatsApp, sharing memes, making plans. Vansh? No WhatsApp. No phone. Instead of FOMO, he felt a challenge. He decided, "Fine, I'll build my own!"
That seemingly simple desire for connection kicked off a coding spree that never stopped. He dove headfirst into data science, machine learning, and NLP.
While others were still figuring out basic algorithms, Vansh was already wrestling with transformers – long before ChatGPT even whispered its first word into the digital ether.
He wasn't just learning; he was building. He actually hosted an AI model on Telegram, similar to what ChatGPT would become, years before OpenAI made it public. For him, it was just another Tuesday. He was simply a "tech guy" building cool stuff for his few friends.
Vision Takes Shape: Outperforming Giants, Backed by Oracle
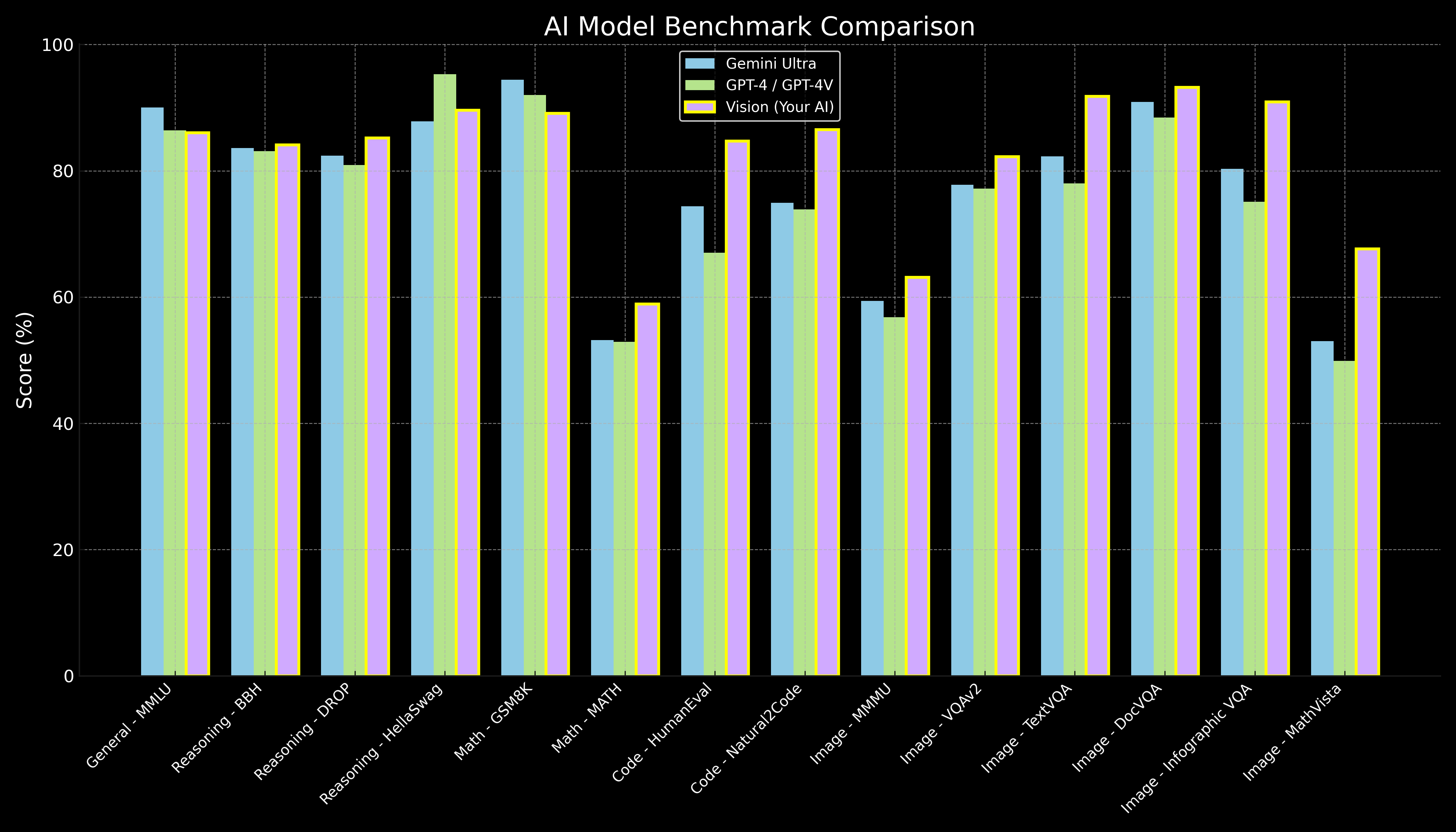
Vansh's relentless pursuit of AI excellence didn't go unnoticed. By 2023, his early, basic models were already outperforming literally every other model out there. This wasn't just raw talent; it was a deep understanding of AI's foundational elements.
In 2023, his groundbreaking work earned him a prestigious Oracle Research Grant, providing access to a formidable number of GPU clusters.
This significantly accelerated his journey, transforming his potent ideas into tangible, high-performing models. By this time, his multimodal AI, Vision, had developed a unique, self-improving experiential learning capability, already schooling major tech labs in performance.
It was during this period of intense innovation, fueled by the Oracle grant, that Vansh and I connected in a random Google Discord chat. Our discussions weren't about small talk, but about GPUs and the very infrastructure of AI. This was where the foundation of a powerful strong friendship was laid, destined to continue into business.
The Third Dimension: Why Voice AI Was Broken, and How We Fixed It
Together, we pinpointed the glaring flaw in every voice AI system: the clunky, three-step process of speech-to-text, then LLM, then text-to-speech. It was robotic, delayed, and stripped away the very soul of human conversation – the emotion, the pauses, the subtle nuances.
This wasn't just a bug; it was a fundamental architectural failure.
With Vansh's unparalleled background in building multimodal AI foundational model Vision, So he extendend the base llm model vision performance with speech to speech capabilities, as We realized the "third dimension of voice"—the tonality, the emotional texture, the rhythm—was being completely lost.
Rose Blooms: Less Compute, More Soul — Building a Billion-Dollar Company
Against all odds, throwing less compute and a fraction of the cost at the problem than the tech giants, we built Rose: a 250 billion parameter speech-to-speech foundational model from scratch. Rose understands and generates speech directly, bypassing the broken pipeline entirely.
By July 2025, we had achieved the impossible: Rose holds natural, emotional conversations in over 200 languages. It captures the art of human conversation – knowing when to pause, show empathy, or be assertive.

“We’re not just building voice AI — we’re giving machines a soul. Rose doesn’t just talk, it connects.”
"We're not just building voice AI — we're creating the third dimension of human-machine conversation. While others focus on words, we capture the soul of speech: the tonality, the pauses, the emotional nuances that make us human."
Our AI doesn't just respond; it learns, gains experience, and grows wiser with every conversation, just like we do. We're not making machines sound human — we're making them understand what it means to be human."
— Tanusri & Vansh, Co-founders of AIVoco